

I was feeling confused & overwhelmed in the RNN's learning process :
So I wrote the RNN world learning Evolution in short to map my learning process
This cleared my 100% confusion.
Now next is "Attention is all you Need" https://t.co/LZiMTeaNrc
So I wrote the RNN world learning Evolution in short to map my learning process
This cleared my 100% confusion.
Now next is "Attention is all you Need" https://t.co/LZiMTeaNrc


3
0
14
2.9K
0

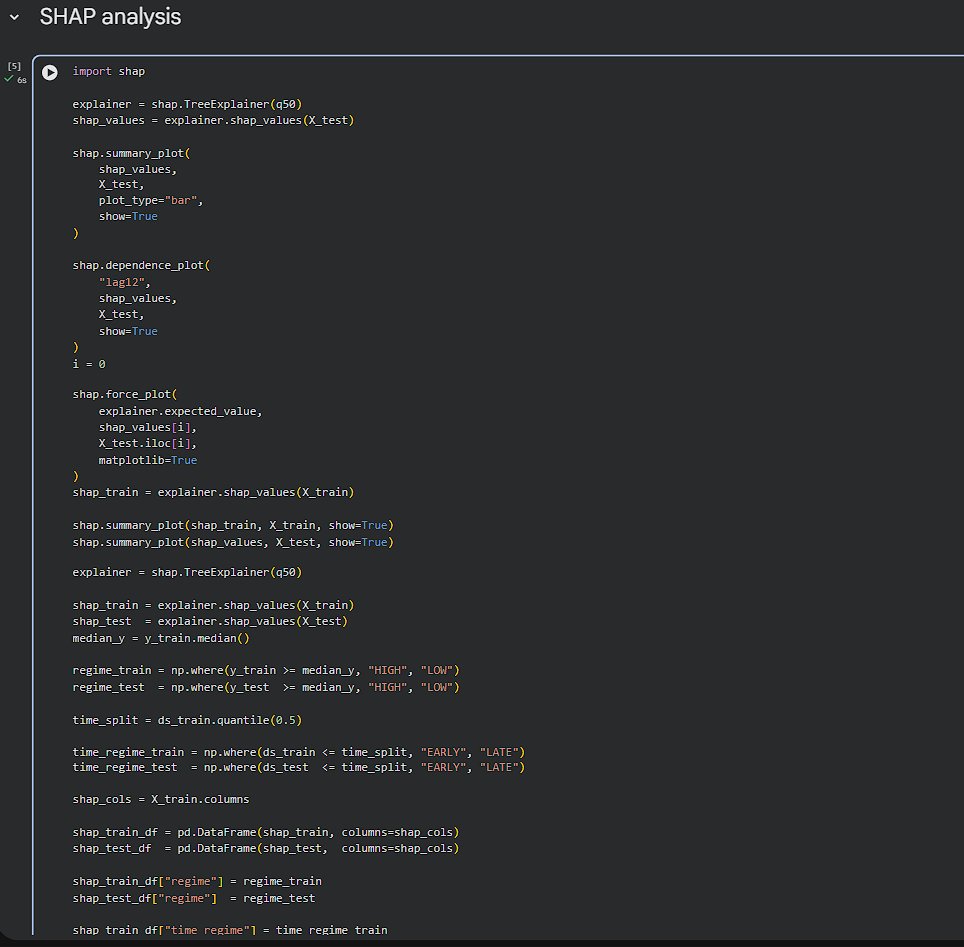
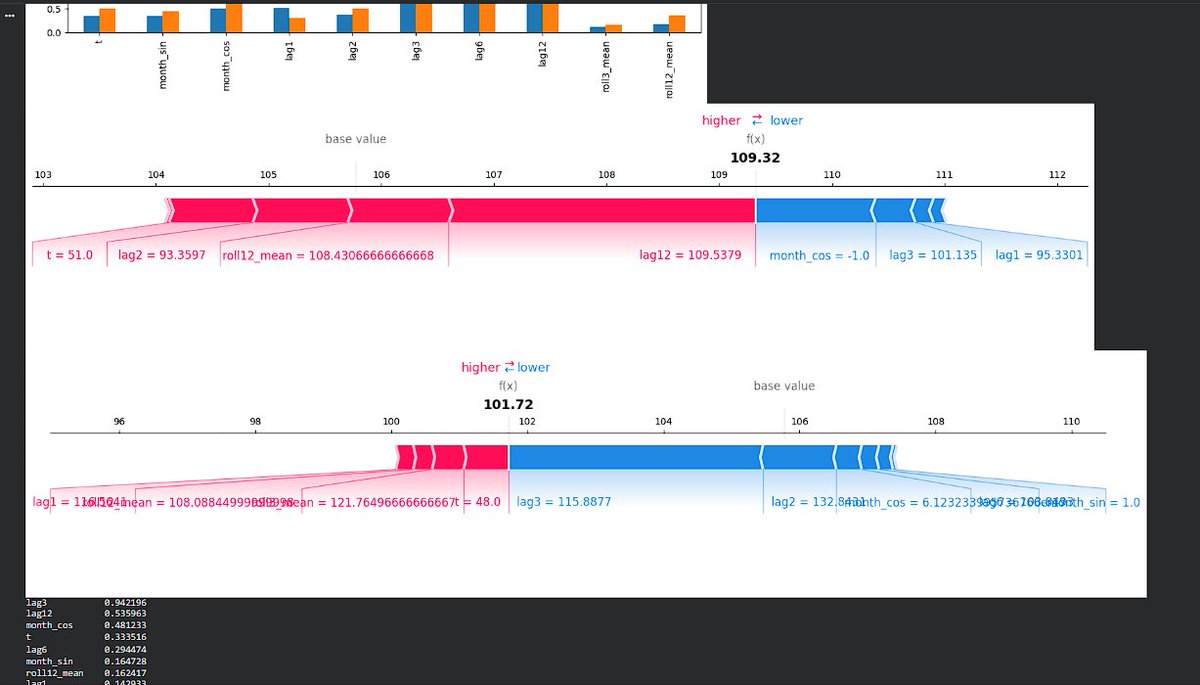
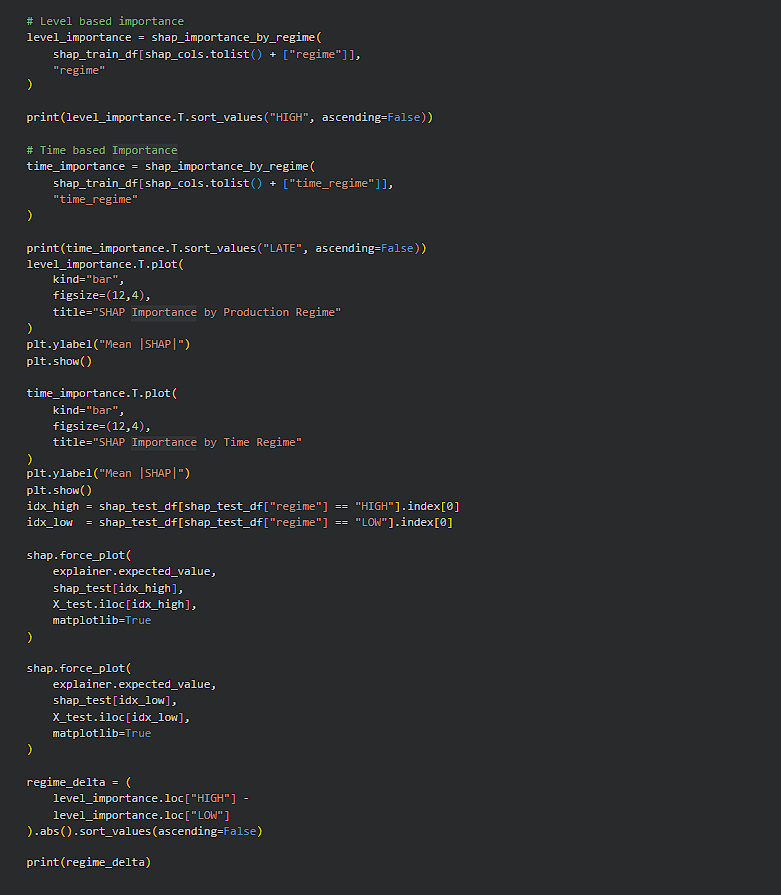
Day 254 : DataScience Journey
Using industrial electricity production data, optimising probabilistic time-series forecasting model and then applied regime-aware SHAP to answer a practical question: does the model think the same way during different economic phases? SHAP was used https://t.co/LNDLIla21L
Using industrial electricity production data, optimising probabilistic time-series forecasting model and then applied regime-aware SHAP to answer a practical question: does the model think the same way during different economic phases? SHAP was used https://t.co/LNDLIla21L

1
0
9
4.4K
0
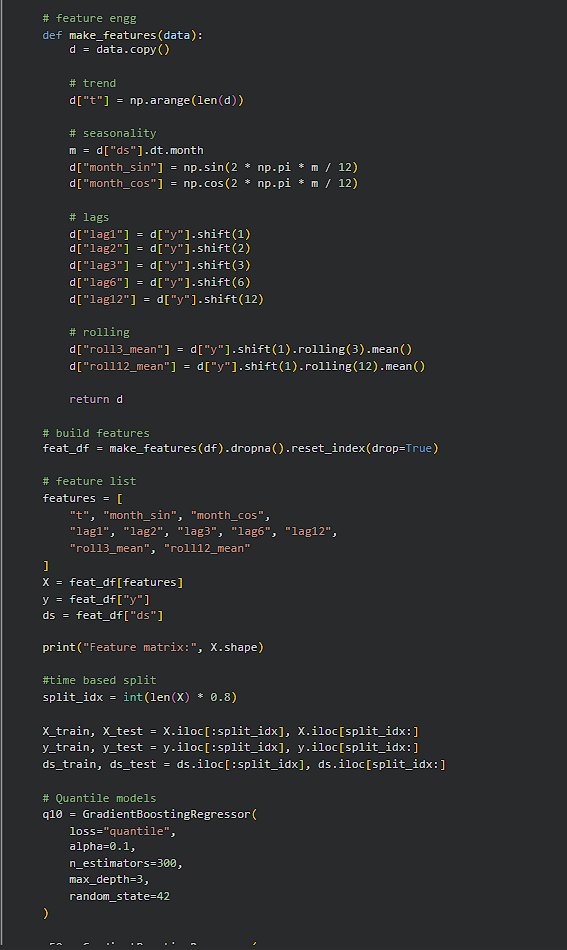
Day 253 : DataScience Journey
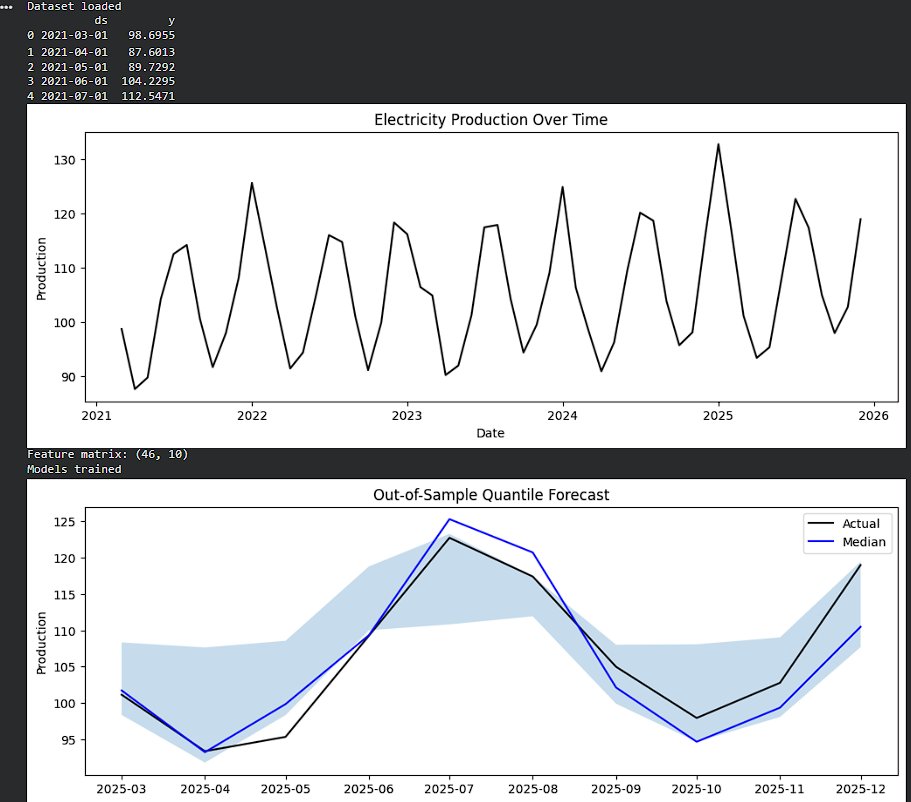
A single forecast looks confident.
But confidence without uncertainty is usually misleading.
I stopped trusting models that give one number
and started building ones that explain how wrong they might be,Instead of point forecasts, I modeled https://t.co/Auo5huDT2M
A single forecast looks confident.
But confidence without uncertainty is usually misleading.
I stopped trusting models that give one number
and started building ones that explain how wrong they might be,Instead of point forecasts, I modeled https://t.co/Auo5huDT2M

1
0
10
4.7K
0
The work of 28 & 29 Jan:
- LSTM's revision
- In depth GRU's learning
- Deep RNN's
- Bi-Directional RNN's
Next some sentiment analysis on Quora Duplicate Questions Dataset
Eager to start with Transformers ! https://t.co/CZrXQ6BLR4
- LSTM's revision
- In depth GRU's learning
- Deep RNN's
- Bi-Directional RNN's
Next some sentiment analysis on Quora Duplicate Questions Dataset
Eager to start with Transformers ! https://t.co/CZrXQ6BLR4

0
0
11
7.4K
0
Day 247 : DataScience Journey
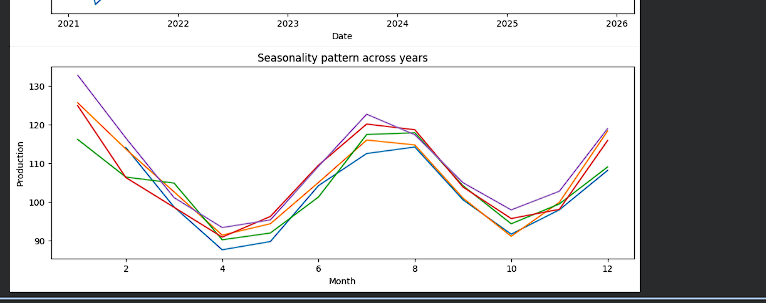
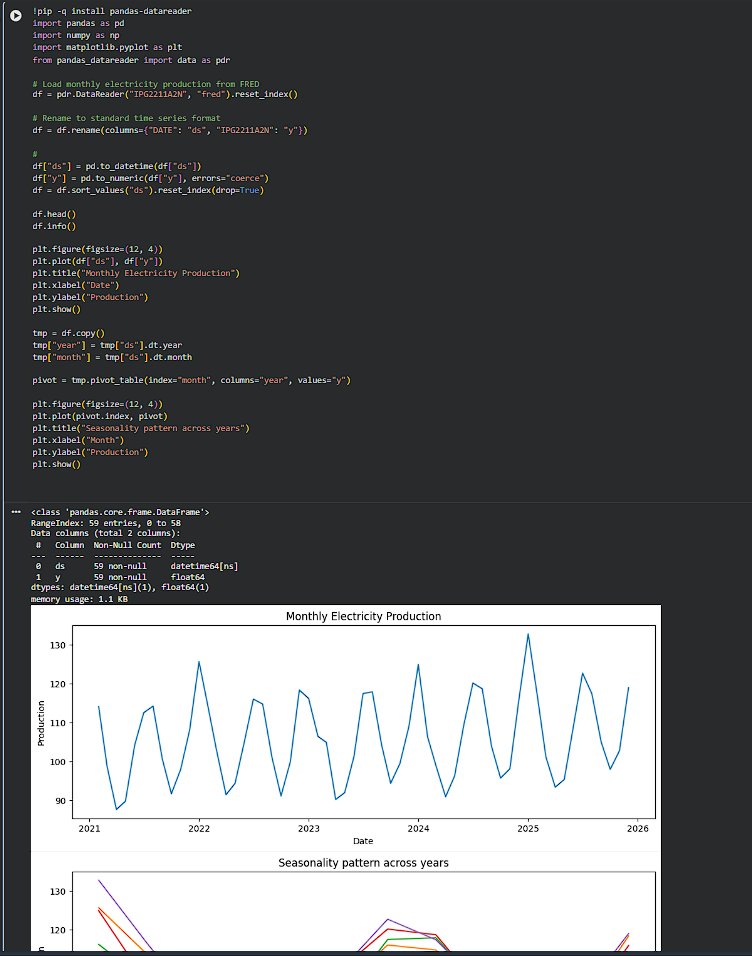
Started with a new dataset today; monthly electricity production and spent time just understanding the data before jumping into models. seasonality plt across yrs made things very clear. The shape repeats every year, but the amplitude isn’t constant. https://t.co/9zszV9VBc6
Started with a new dataset today; monthly electricity production and spent time just understanding the data before jumping into models. seasonality plt across yrs made things very clear. The shape repeats every year, but the amplitude isn’t constant. https://t.co/9zszV9VBc6

2
0
9
2.7K
0
Introducing Ramartha —
> a computational framework for semantic and narrative analysis of Shri Ramcharitmanas
> It models meaning at the verse and narrative level
> enabling concept-driven exploration in a low-resource NLP setting
> build live app:
https://t.co/p8hhhb4ydZ https://t.co/kAeySjAJg9
> a computational framework for semantic and narrative analysis of Shri Ramcharitmanas
> It models meaning at the verse and narrative level
> enabling concept-driven exploration in a low-resource NLP setting
> build live app:
https://t.co/p8hhhb4ydZ https://t.co/kAeySjAJg9
3
1
14
7.4K
1
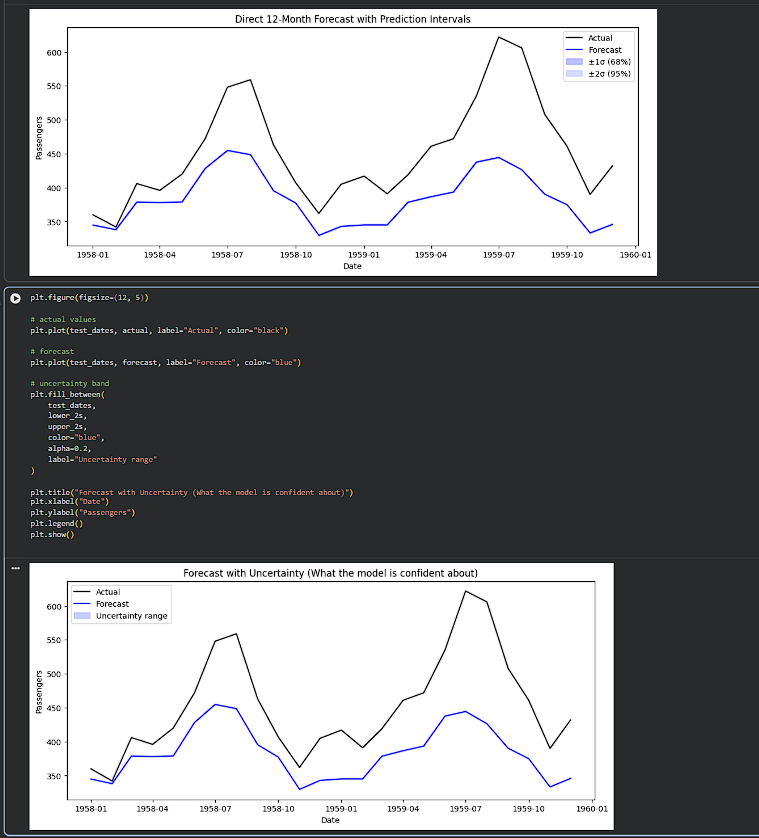
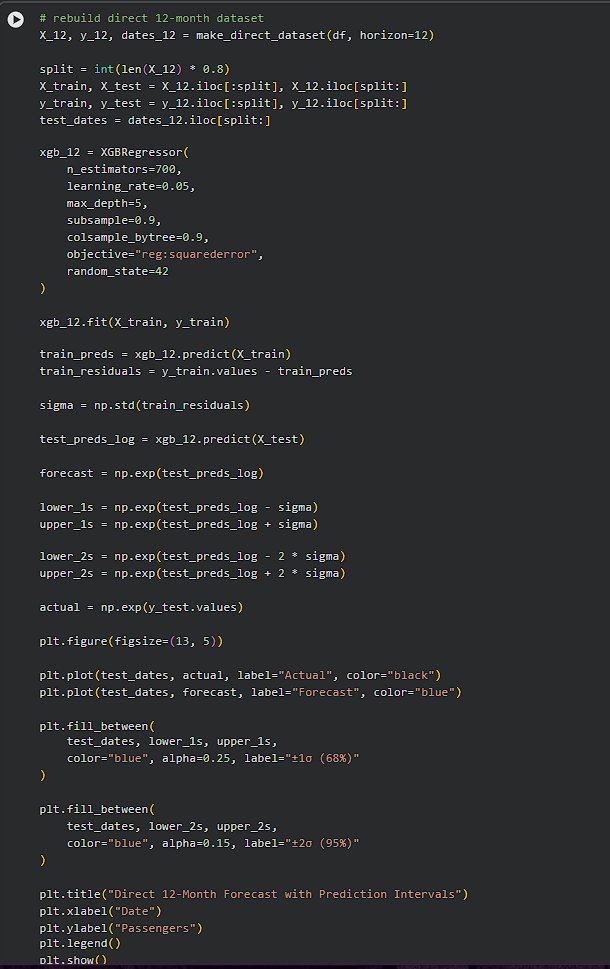
Day 246 : DataScience Journey
This phase really connected the dots for me. After building direct multi-step forecasts with XGBoost, I added prediction intervals using residual-based uncertainty. Technically it’s just estimating error spread, but the plots made the idea of https://t.co/fibFKGezma
This phase really connected the dots for me. After building direct multi-step forecasts with XGBoost, I added prediction intervals using residual-based uncertainty. Technically it’s just estimating error spread, but the plots made the idea of https://t.co/fibFKGezma

1
0
9
1.2K
0
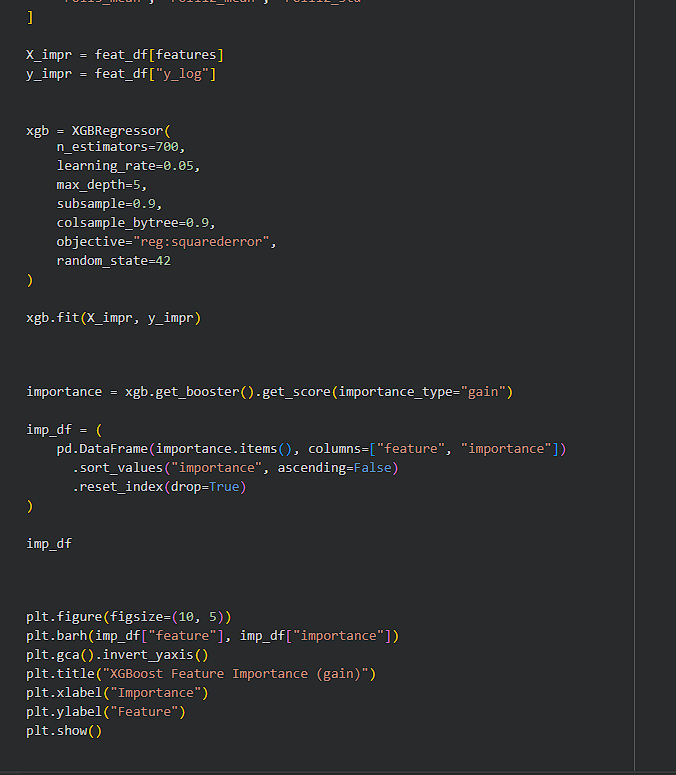
Day 244 : DataScience Journey
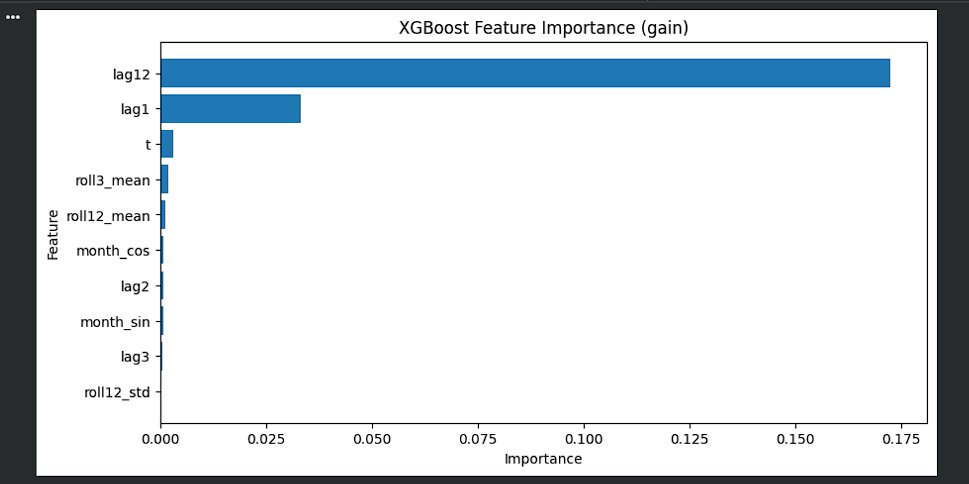
Checked XGBoost feature importance today and the model made its priorities very clear lag-12 is doing most of the heavy lifting, which makes sense because this data is all about yearly seasonality. lag-1 still matters (recent momentum), and the trend https://t.co/REqCm7bRtt
Checked XGBoost feature importance today and the model made its priorities very clear lag-12 is doing most of the heavy lifting, which makes sense because this data is all about yearly seasonality. lag-1 still matters (recent momentum), and the trend https://t.co/REqCm7bRtt

2
0
8
4.0K
0
Day 241 : DataScience Journey
Not gonna lie, time series is slowly teaching me humility.
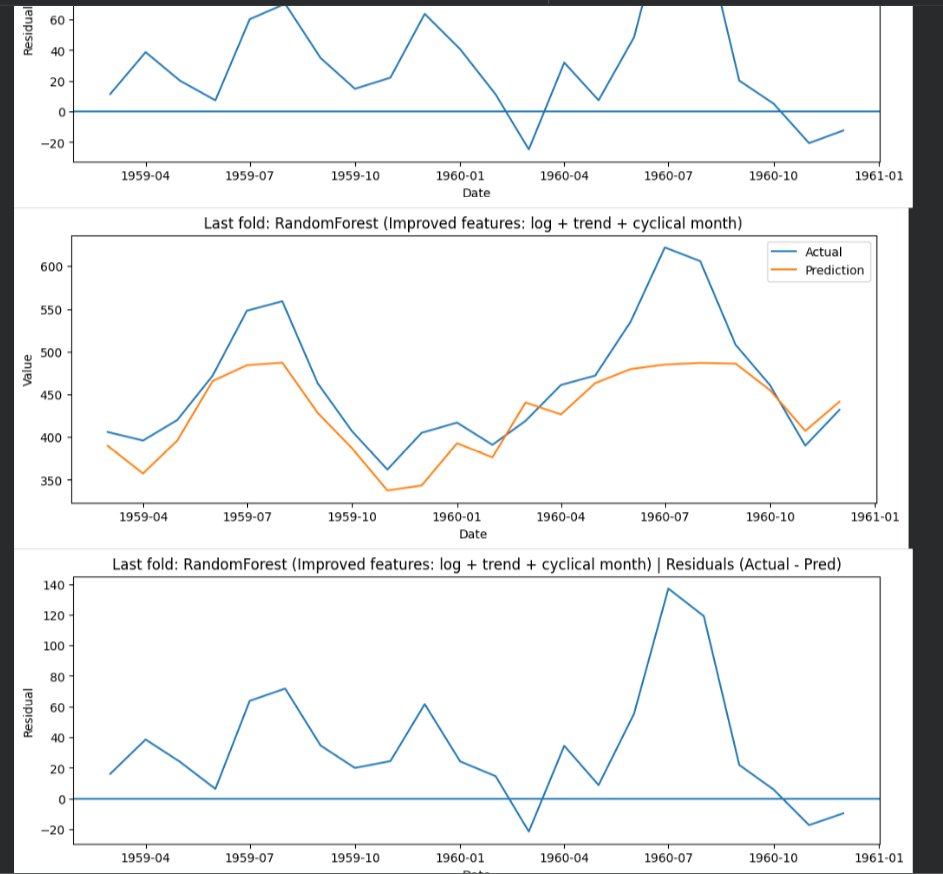
I thought adding “better features” would instantly fix the forecast, but it doesn’t work like that, compared a basic feature set (lags + rolling stats + month) against an improved one where I https://t.co/UXh74DiSIe
Not gonna lie, time series is slowly teaching me humility.
I thought adding “better features” would instantly fix the forecast, but it doesn’t work like that, compared a basic feature set (lags + rolling stats + month) against an improved one where I https://t.co/UXh74DiSIe


1
0
11
3.7K
2

Want projects that make your portfolio stand out? Check this out:https://t.co/51XQi6Kdis https://t.co/x39rU1r192

0
3
9
1.4K
8
Coding till 24:00 ;) https://t.co/XpPjzOtkhb
1
0
16
4.9K
0
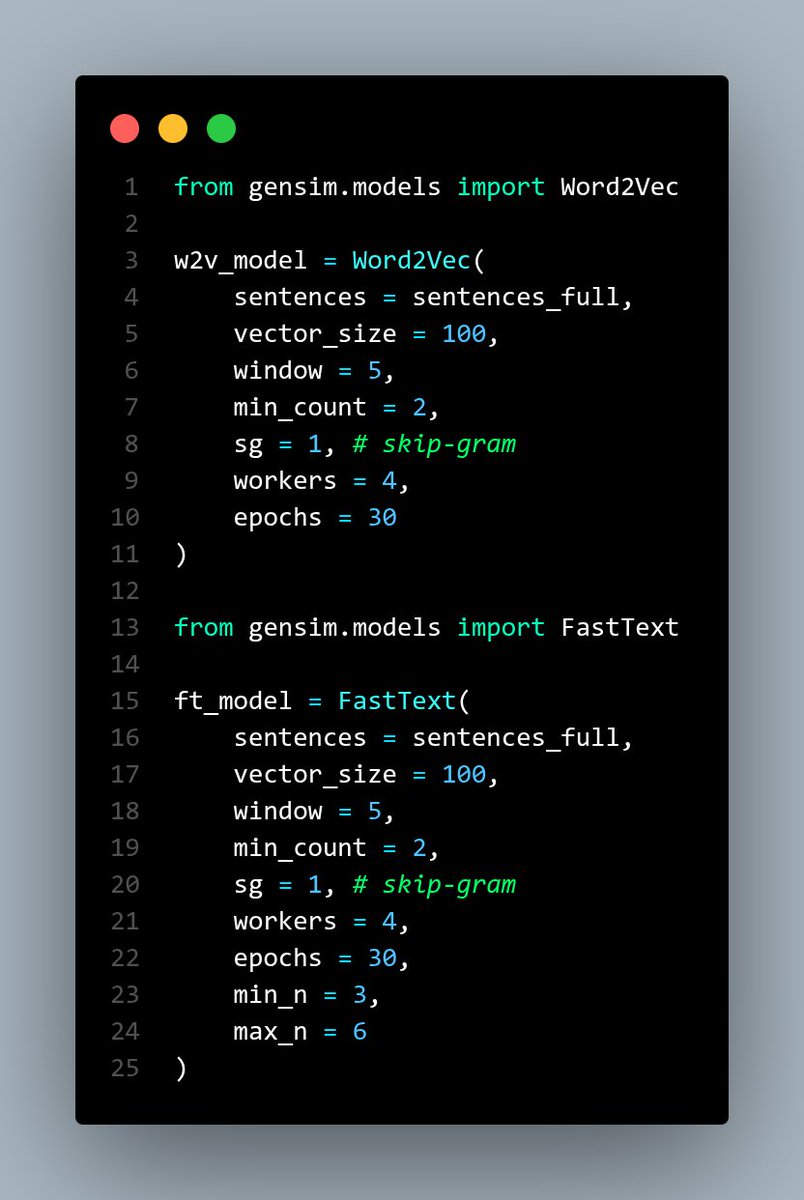
Working on A Low-Resource NLP Project - Linguistic Analysis on ShriRamcharitmanas
> Using Sanskrit/Awadhi language
> Training the Word2Vec & FastText models
> Comparing both models on Word level & Verse level Semantics
> Eager to complete this project and share it with you all :) https://t.co/OoyTV7tRjq
> Using Sanskrit/Awadhi language
> Training the Word2Vec & FastText models
> Comparing both models on Word level & Verse level Semantics
> Eager to complete this project and share it with you all :) https://t.co/OoyTV7tRjq

0
0
8
2.0K
0
need some honest feedback on my resume, roast away and tell me what to fix to get a ml internship https://t.co/Mb5wXLaEvJ

6
0
23
9.6K
3
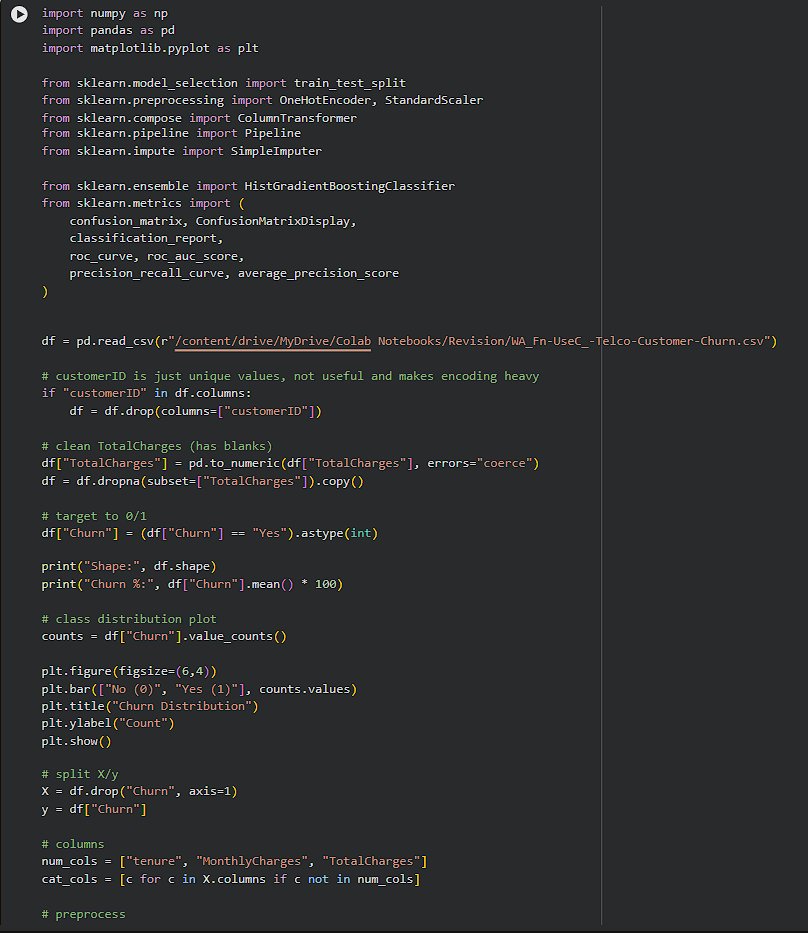
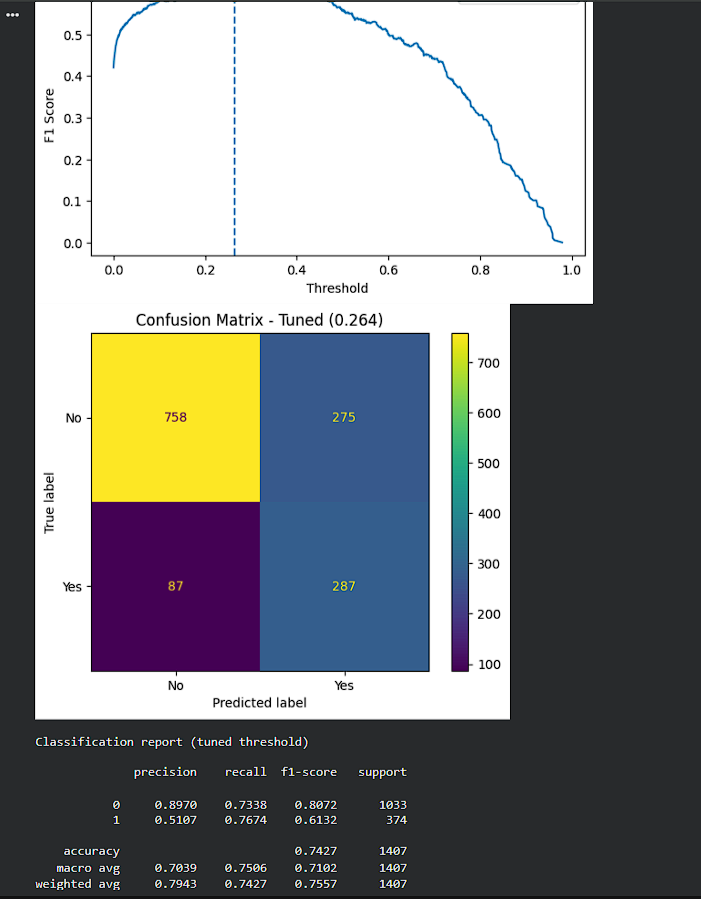
Day 236 : DataScience Journey
Today’s work on the Telco Churn dataset. The first real hurdle was the data itself, TotalCharges looked numeric but had blank values stored like text, so converting it and dropping invalid rows was necessary before anything meaningful could happen https://t.co/JXpci7ndSe
Today’s work on the Telco Churn dataset. The first real hurdle was the data itself, TotalCharges looked numeric but had blank values stored like text, so converting it and dropping invalid rows was necessary before anything meaningful could happen https://t.co/JXpci7ndSe


2
1
10
6.1K
1
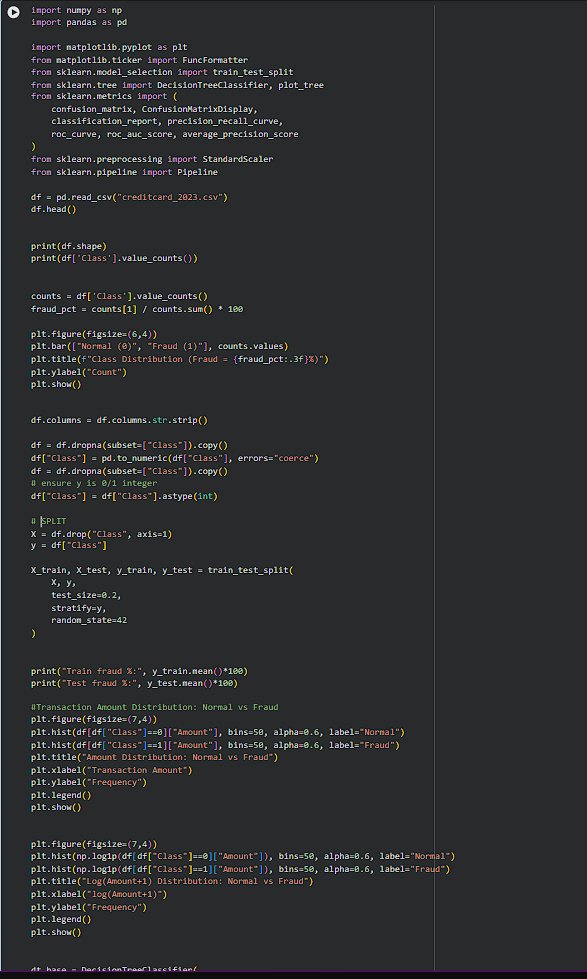
Day 235: DataScience Journey
A real fraud detection system isn’t about building the “best model”… it’s about catching suspicious
transactions without flagging everything and wasting manual review.
That’s what makes it tricky although are rare, but missing one can be expensive. https://t.co/lQphjhDfDb
A real fraud detection system isn’t about building the “best model”… it’s about catching suspicious
transactions without flagging everything and wasting manual review.
That’s what makes it tricky although are rare, but missing one can be expensive. https://t.co/lQphjhDfDb

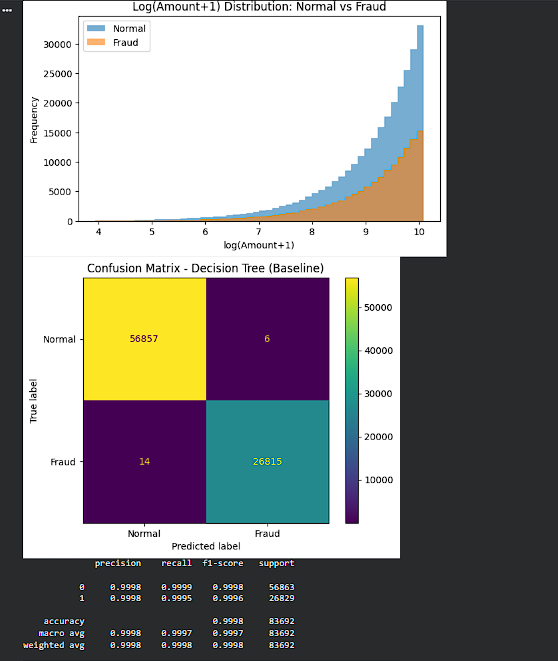

1
0
9
3.8K
0
Day 234: Data Science Journey
Logistic Reg. is one of those topics that looks basic on paper, but hits different when you actually run it and see the boundary forming. The main thing that stood out was how it’s not just predicting 0/1, it’s giving a prob. like “how sure am I?”. https://t.co/9cfEf91HJG
Logistic Reg. is one of those topics that looks basic on paper, but hits different when you actually run it and see the boundary forming. The main thing that stood out was how it’s not just predicting 0/1, it’s giving a prob. like “how sure am I?”. https://t.co/9cfEf91HJG
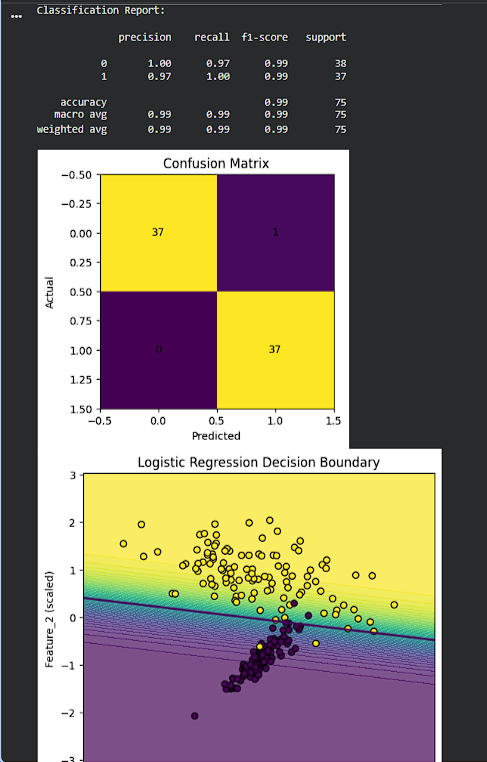
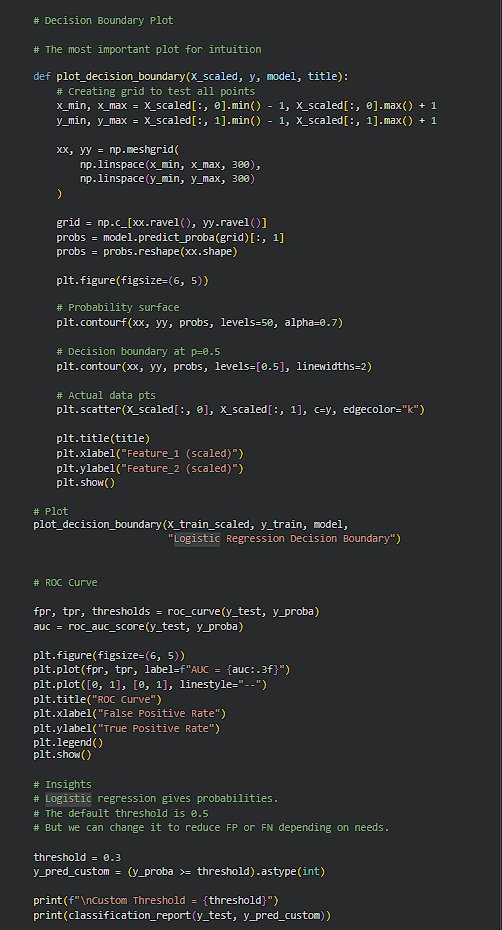
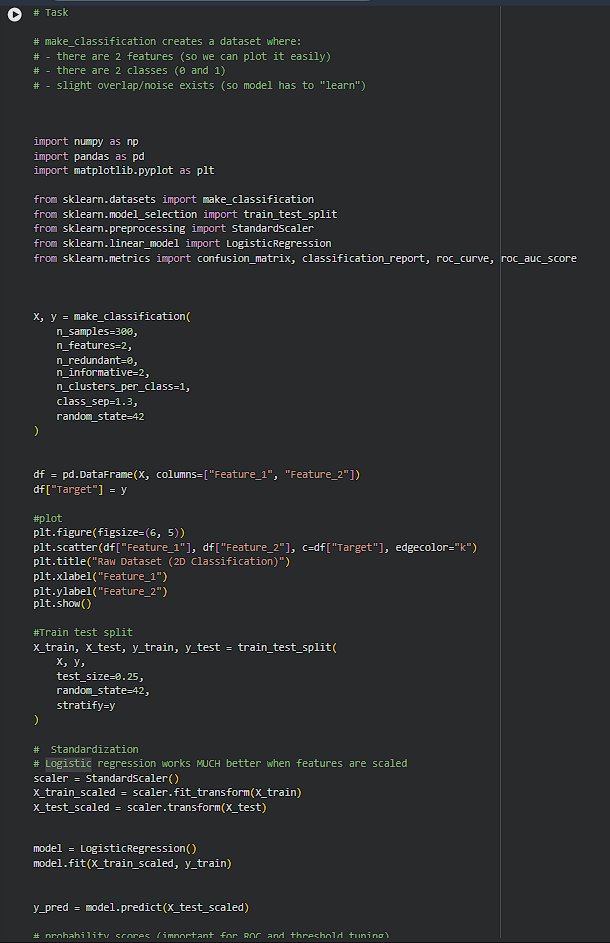

1
0
9
5.7K
0
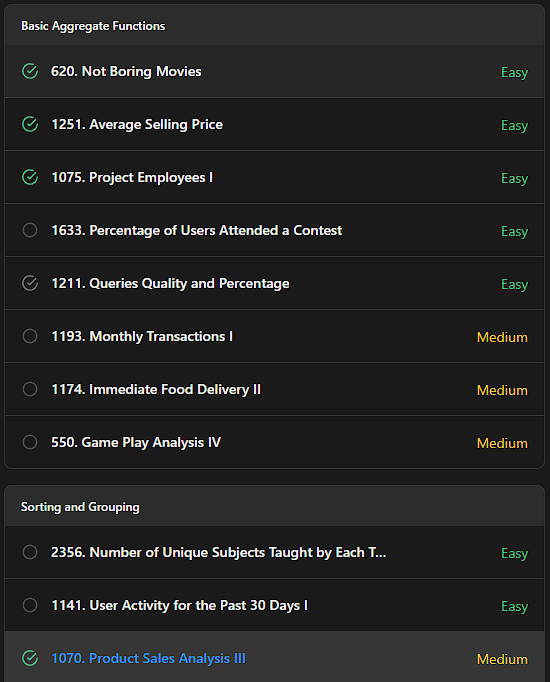
Day 232 : Data Science Journey
Today’s session felt genuinely productive, practiced a bunch of SQL ques on aggregate functions and grouping (like Average Selling Price, etc.) and it’s slowly starting to feel less like “writing queries” & more like pulling real insights.
Then https://t.co/T2WvfhfVlJ
Today’s session felt genuinely productive, practiced a bunch of SQL ques on aggregate functions and grouping (like Average Selling Price, etc.) and it’s slowly starting to feel less like “writing queries” & more like pulling real insights.
Then https://t.co/T2WvfhfVlJ

1
0
9
3.0K
0
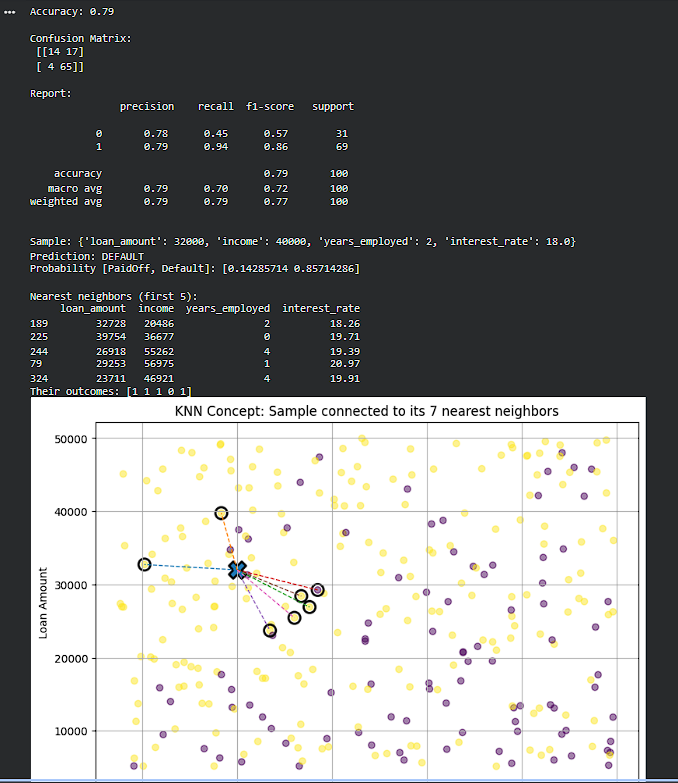
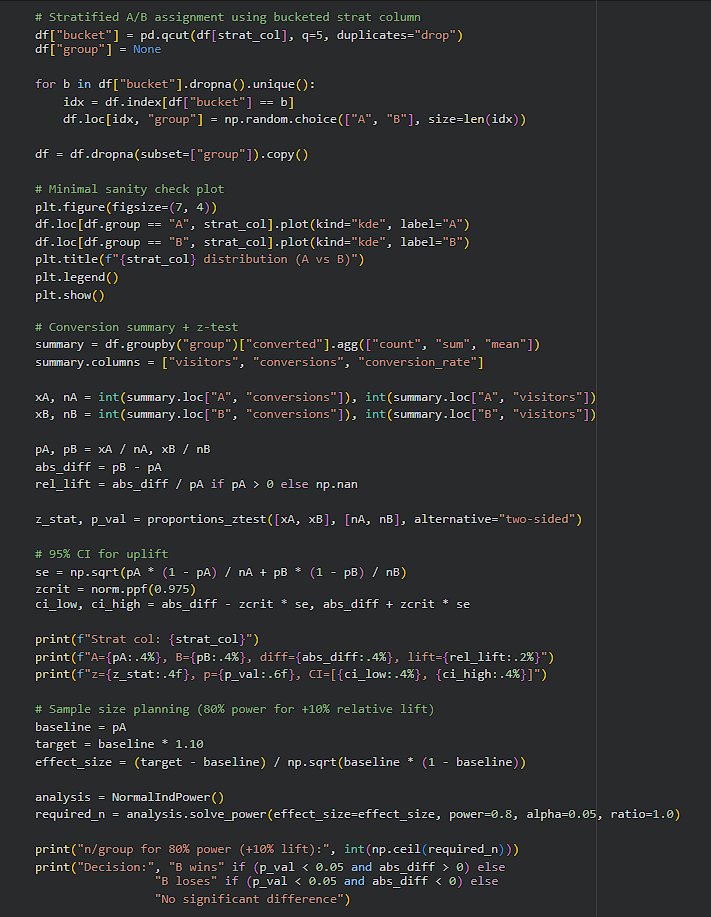
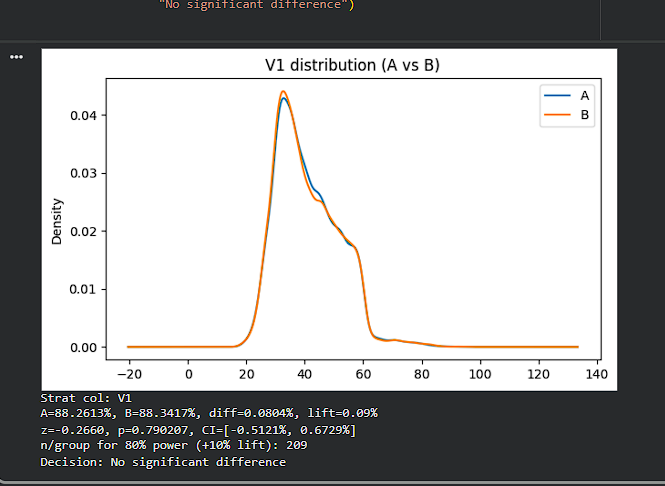
Day 231 : Data Science Journey
Today, did A/B testing the right way, used the Bank Marketing dataset and treated it like a real product experiment: created a conversion metric (subscribed = 1), split users into Control (A) and Variant (B), and then actually verified that the https://t.co/7rKOrZdjB7
Today, did A/B testing the right way, used the Bank Marketing dataset and treated it like a real product experiment: created a conversion metric (subscribed = 1), split users into Control (A) and Variant (B), and then actually verified that the https://t.co/7rKOrZdjB7
2
0
13
5.0K
2
Just dropped a deep dive blog on LSTM
Why vanilla RNNs break, how gates control memory, and how stable sequence learning actually works —intuition → math → code.
If LSTM ever felt like magic, this blog reverse-engineers it.
- Give it a read of 5 mins
https://t.co/gegoHn9WoC https://t.co/fcw8ldCyEt
Why vanilla RNNs break, how gates control memory, and how stable sequence learning actually works —intuition → math → code.
If LSTM ever felt like magic, this blog reverse-engineers it.
- Give it a read of 5 mins
https://t.co/gegoHn9WoC https://t.co/fcw8ldCyEt
1
1
13
6.5K
2
After a long time, I finally wrote a new blog
Why 97% Is Not Enough Building a high-sensitivity pneumonia screening system with DenseNet & Grad-CAM
• ~10 min read
• Real project learnings & why safety>accuracy ?
• give it a read 🙂
Enjoy reading : )
https://t.co/rmB81tAPjX https://t.co/YViOL2EZmv
Why 97% Is Not Enough Building a high-sensitivity pneumonia screening system with DenseNet & Grad-CAM
• ~10 min read
• Real project learnings & why safety>accuracy ?
• give it a read 🙂
Enjoy reading : )
https://t.co/rmB81tAPjX https://t.co/YViOL2EZmv
0
1
11
3.8K
0
Crafting objective proof from vast and ambiguous datasets. Validating a chosen path to enable confident, decisive action. #100DaysOfML
466 Followers
11 Contributions
Africa's biggest Data Ed Tech platform, changing the narrative and equipping the next generation of Tech workforce
2.1K Followers
1 Contributions
30.7K
Total Members
+ 3
24h Growth
5
7d Growth
Date Members Change
Jun 15, 2026 30.7K +3
Jun 14, 2026 30.7K -1
Jun 13, 2026 30.7K +2
Jun 12, 2026 30.7K -3
Jun 11, 2026 30.7K -4
Jun 10, 2026 30.7K -2
Jun 9, 2026 30.7K +3
Jun 8, 2026 30.7K +0
Jun 7, 2026 30.7K +1
Jun 6, 2026 30.7K +1
Jun 5, 2026 30.7K -1
Jun 4, 2026 30.7K +2
Jun 3, 2026 30.7K +5
Jun 2, 2026 30.7K —
No reviews yet
Be the first to share your experience!
Share Your Experience
Sign in with X to leave a review and help others discover great communities
Login with XLoading...
Welcome! This is a repository of the daily ML/Data Science tweets of Dr. Theophano Mitsa. ML/Data Science tweets/comments from community members are encouraged!
Community Rules
Be kind and respectful.
Keep Tweets on topic.
Explore and share.
No foul language