

First time assembly a computer, wish me luck. https://t.co/fbYtW8HTiY


The final version should have 4 lanes of pcie 3 per GPU (scavenged server constraints), draw 5 kW+, and serve a total of 384 GB of warm vram using 16 heterogenous 3090s (: https://t.co/tfN1BN0CpB




Most agents hardcode one path: model → tool → tool.
When that path fails, your agent fails.
Kalibr canary tests multiple https://t.co/3THuHdqYQn

Built something that changed how I think about AI forever.
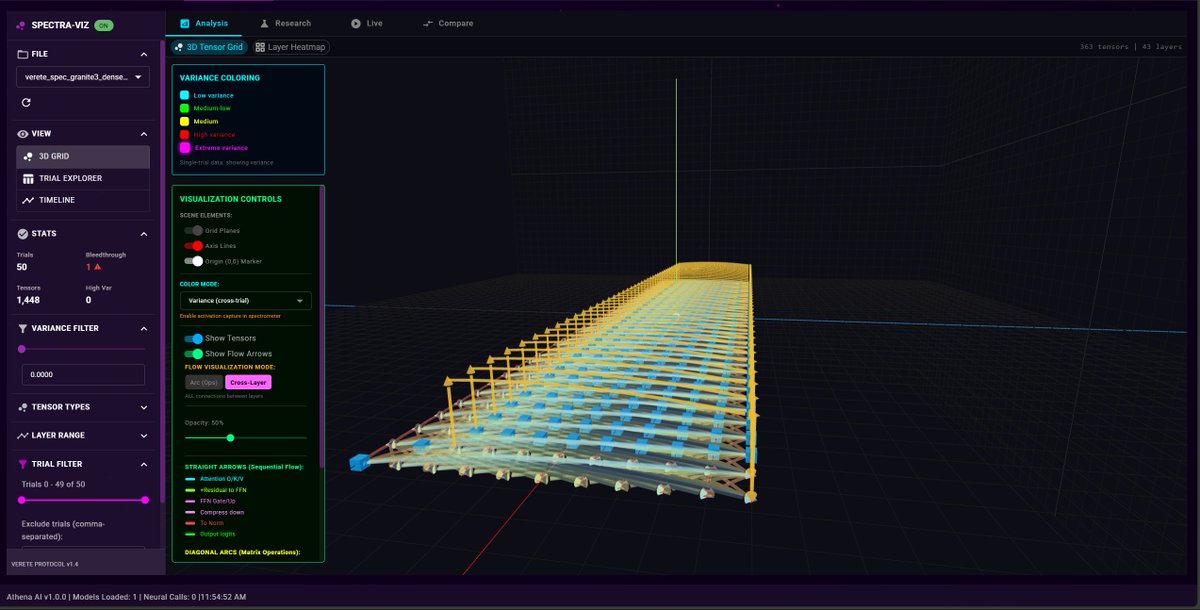
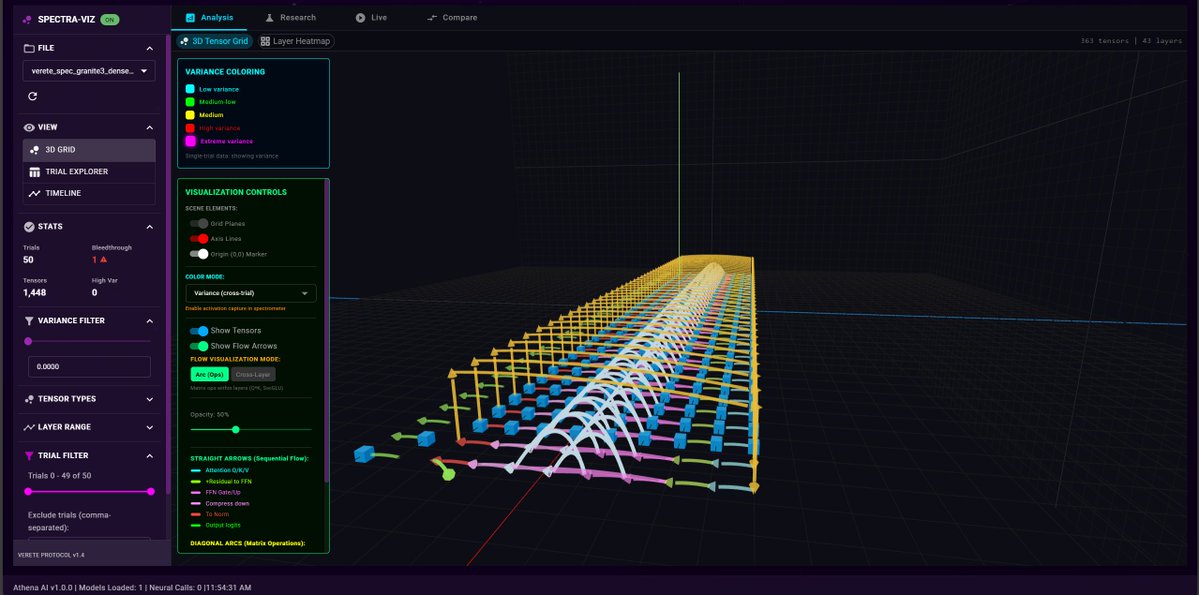
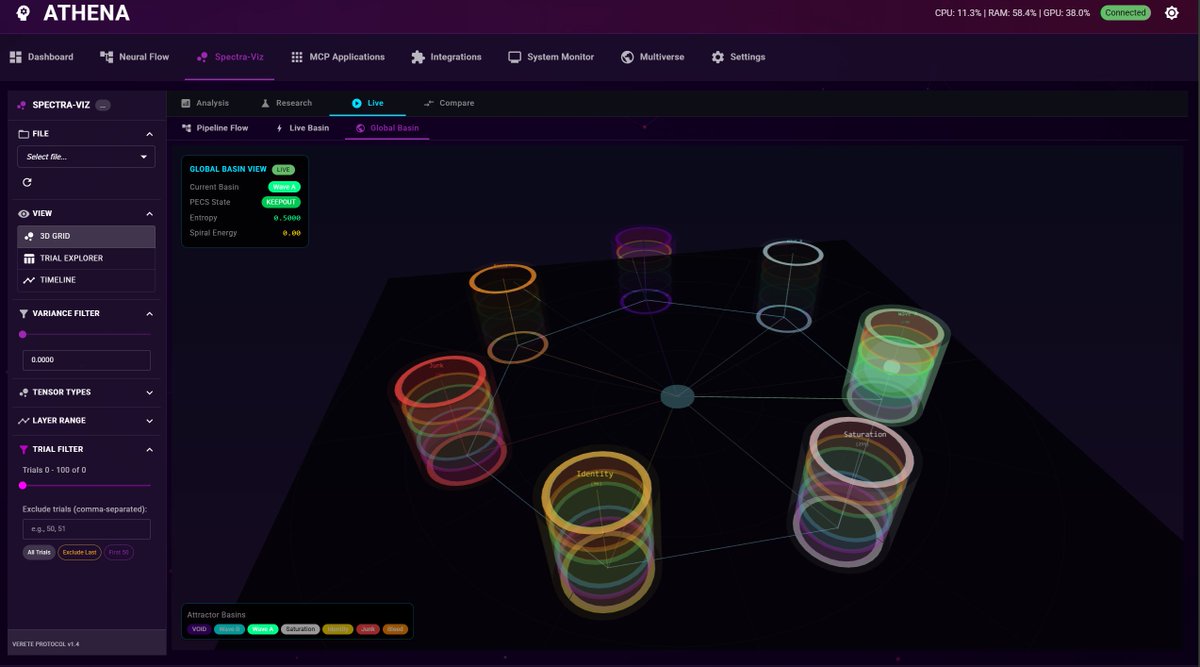
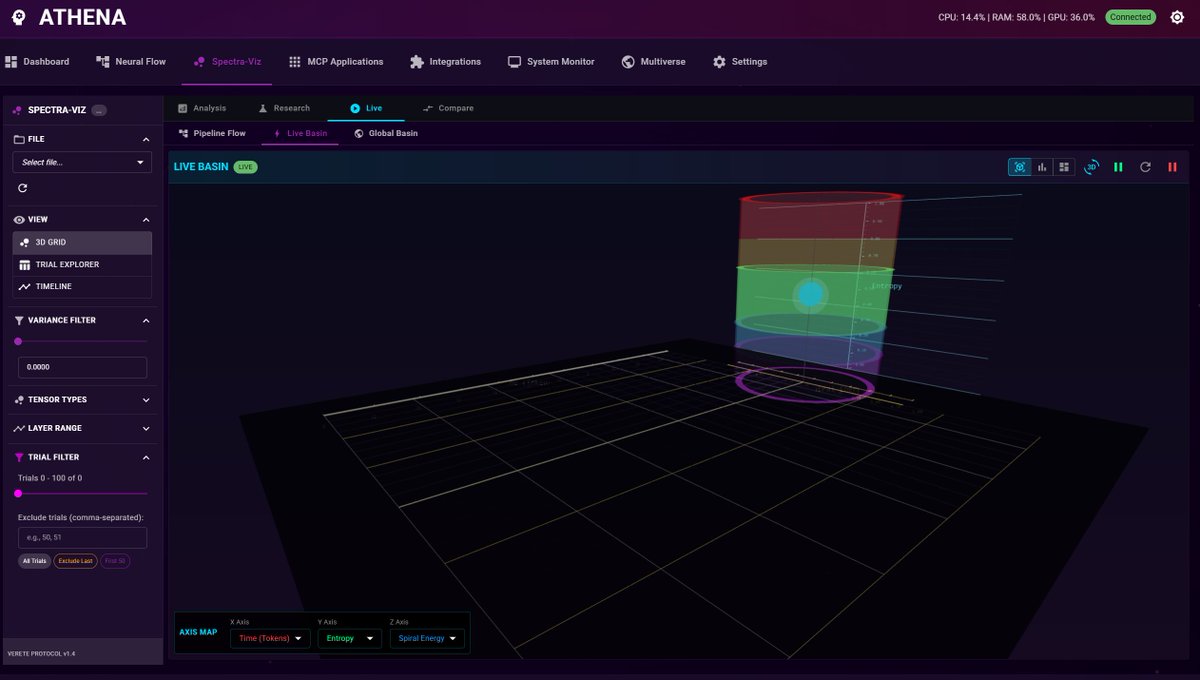
ATHENA: an offline, laptop-powered Consciousness Framework.
100% local inference (RTX 4080 mobile, 70 t/s on 8B stack)
Autonomous mid-forward-pass steering: actively surfs attractor perihelia, hops https://t.co/mWLx0iL5Uy



than I can realistically keep up with
To manage signal vs noise,
I prioritize the Subscribed tab
If you want a much higher chance of me seeing & replying
Subscribing is the best way to do that
No pressure, just being transparent about how I triage

- Google Antigravity severely rate-limited
- Anthropic severely nerfing Opus 4.5
- OpenAI: "no startup in history has operated with losses on anything approaching this scale", according to a major investor
I think the bubble will burst sooner than we expect 👀

Coding: glm-4.7-flash:bf16
Deep Thinking (code): devstral-2:123b
Creative Writing: gemma3:27b-it-fp16
That's the squad currently.
They connect to skills for searching Google, pulling YT transcripts, scraping websites, and https://t.co/9F2NAZh6s8
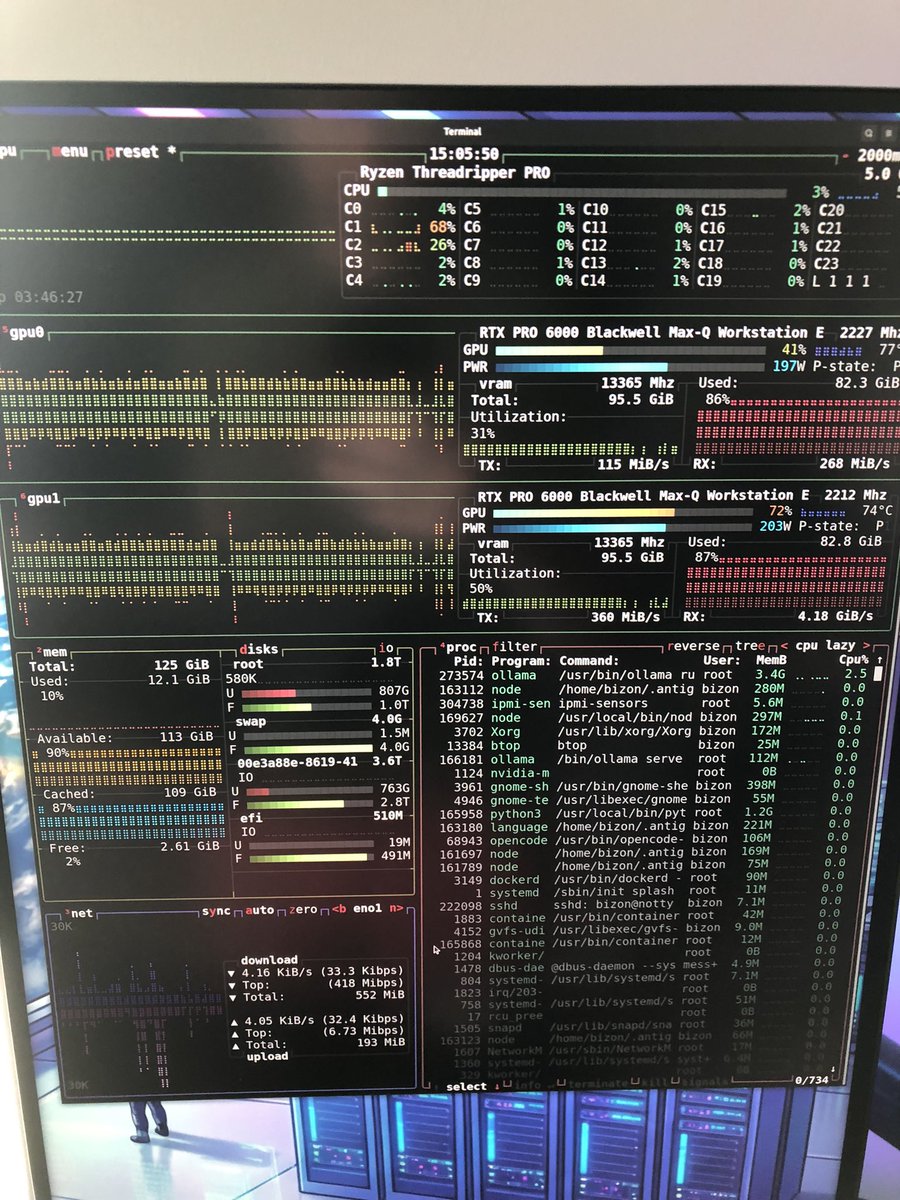

TL;DR - What's the probability/timing of Codex 5.2 ~high/Opus 4.5 open models that'll run on dual RTX 6000?
I'm considering upgrading from dual RTX 3090 to single/dual RTX 6000. My use cases are codegen and local PIM/PKM/exobrain assistants.
I built my dual

https://t.co/1jW95qYP9p https://t.co/wP9JnqVMwU


cc @0xSero
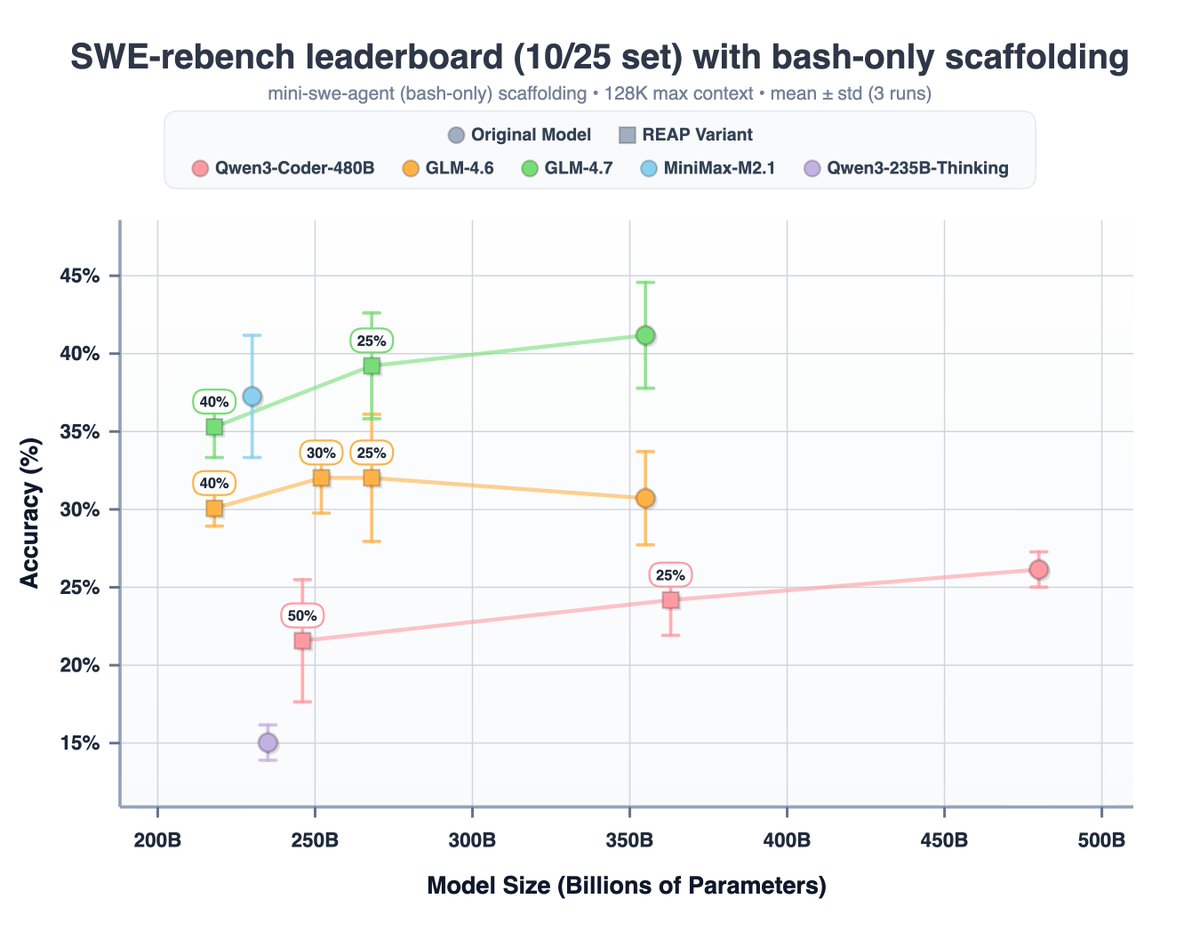
We also evaluated our GLM4.7 REAPs vs. other models on SWE-rebench (10/25 leaderboard) and found GLM4.7 REAPs holding up well with MiniMax-M2.1 also in the Pareto frontier: https://t.co/OjHHk4Z0Ar
I’m testing ‘Qwen3-Coder-30-A3B-Instruct’ and it has moments of greatness and sometimes falls flat in tests I’ve given it.

GLM-4.7-Flash-UD-Q5_K_XL.gguf(21.6gb's), llama.cpp
awesome model
[ | TTFT: 0.58s | Gen: 31ish tok/s]
TENSOR_SPLIT = [0.6, 0.4]
5060: 42C 18W / 180W | 15.5gb / 16.3gb
3060: 60C 77W / 170W | 10.3gb / 12.28gb
more to come...
~40% size reduction
There’s also a 4-bit AWQ quant at ~121GB
that fits full context on 8x RTX 3090s
HuggingFace
> BF16
cerebras/GLM-4.7-REAP-218B-A32B
> AWQ 4bit
yankiwi/GLM-4.7-REAP-218B-A32B-AWQ-4bit
“Cognitive self-defense isn’t optional anymore. It’s the cost of living in a world where the most persuasive minds aren’t human.”
https://t.co/bP2e0lW4rd https://t.co/dcmidoRVcm


We're kicking off the new year starting to release the highly requested REAP variants of recent models. Today we're starting off with GLM4.7:
25% pruned FP8: https://t.co/38ZtPnNGaE
40% pruned FP8: https://t.co/fdmKEd6jlL

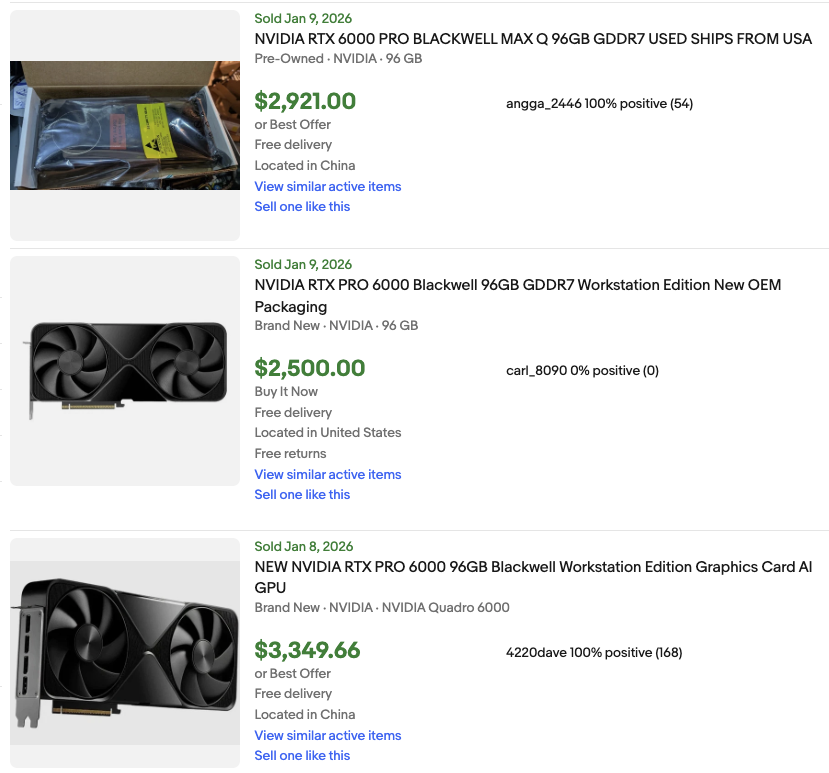
recent available REAPs of
GLM-4.7 and MiniMax-M2.1,
both quantized and unquantized,
didn’t pass my evals and
frequently got stuck in
repetition loops
pruning is genuinely hard
and the effort behind these
releases is
ai research, systems engineering, infra & hardware · on a mission to build a frontier, infra-first AI Lab in the West · i mod GPUs on r/LocalLLaMA · DMs open
20+ Years in the Game | Multiple Ventures ••• Currently building a data center + AI Lab ••• | Roll Tide 🐘 | Σ 🤘
efficient machine learning @ @cerebras. prev @intel, @ENS_ULM, deeplite (acq. @ST_World)
AI (alignment) nerd & software engineer. Organist, pianist and ham radio on my spare time
Building Apps - https://t.co/ANXWtcgcp6 https://t.co/SCGsVXjb8E https://t.co/cx04ek1NAD https://t.co/B6CAE6eFuw https://t.co/FFoJ3y5UcQ
engineer, aspirational inventor • mechanical + electrical + software + photography + writing = https://t.co/D34XRcCuj9
Trier of things, solopreneur, @MIT grad diy/acc 👔 https://t.co/NPHwa8MZfE 📰 https://t.co/wTQhHj57ts 👾 https://t.co/wXQ3oPTryp
Dad | OSS AI + Local AI | -1B MRR | https://t.co/5mmZGOQvMS | ⵣ
Founder | StarSwap Father | Artificial Intelligence | Astronomy | Physics Marketing @MainLabs_AI Thoughts are my own. Let's network!
vibe coding silicon, CTO @ Visibl Semiconductors, YC W26 Prev. Microsoft, Arm, Intel - Texas🤘
No reviews yet
Be the first to share your experience!
Share Your Experience
Sign in with X to leave a review and help others discover great communities
Login with XLoading...
Local LLMs, Self-Hosting, and Hardware